
WordPress教程
网站不想被百度等搜索引擎抓取应该怎么暂时屏蔽?
 PetitQ
PetitQ
收藏

有些站长比较喜欢将站点上线测试(不喜欢在本地测试),但是又不想被百度等搜索引擎抓取,那么应该怎么暂时屏蔽呢?今天就跟大家简单介绍几种方法。
方法一:
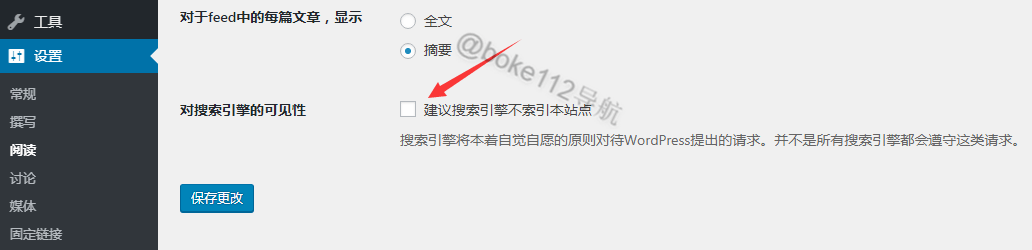
WordPress 站点可以直接登录站点后台 >> 设置 >> 阅读 >> 勾选“建议搜索引擎不索引本站点”并点击【保存更改】即可。
也想出现在这里?联系我们吧

方法二:
直接在网站根目录中新建一个 robots.txt 文件,然后在文件中添加以下代码:
User-Agent: *
Disallow: /
方法三:
通过 noindex 标记来禁止,直接在站点的头文件 header.php 文件中添加以下代码:
<meta name="robots" content="noindex" >
方法四:
通过 PHP 代码禁止(WordPress 站点为例),将以下代码添加到主题目录的 functions.php 当中:
ob_start("Deny_Spider_Advanced");
function Deny_Spider_Advanced() {
$UA = $_SERVER['HTTP_USER_AGENT'];
$Spider_UA = '/(spider|bot|)/i'; //定义需要禁止的蜘蛛 UA,一般是 spider 和 bot
//如果检测到 UA 不为空而且发现是蜘蛛则返回 404if($UA && preg_match_all($Spider_UA,$UA)) {
header('HTTP/1.1 403 Forbidden');
header("status: 403 Forbidden");
}}
可以自行替换或添加以上的 spider|bot,多个用|隔开即可。
方法五:
Nginx 禁止,在 server{}中添加以下代码:
#如果抓取的 UA 中含有 spider 或 bot 时返回 403if ($http_user_agent ~* "spider|bot") {
return 403; #如果是删除已收录的,则可以返回 404
break;
可以自行替换或添加以上的 spider|bot,多个用|隔开即可。
方法六:
Apache 禁止,在.htaccess 中添加以下代码:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (^$|spider|bot) [NC]
RewriteRule ^(.*)$ - [F]
可以自行替换或添加以上的 spider|bot,多个用|隔开即可。
总结
理论上以上 6 种方法都有效,建议找适合自己站点的一种办法来使用即可。一般采用方法二比较普遍,如果能够结合方法五或六来使用估计效果更佳。
专业提供WordPress主题安装、深度汉化、加速优化等各类网站建设服务,详询在线客服!
也想出现在这里?联系我们吧



